
August 6, 2024
Recognizing Loss Function In Deep Knowing
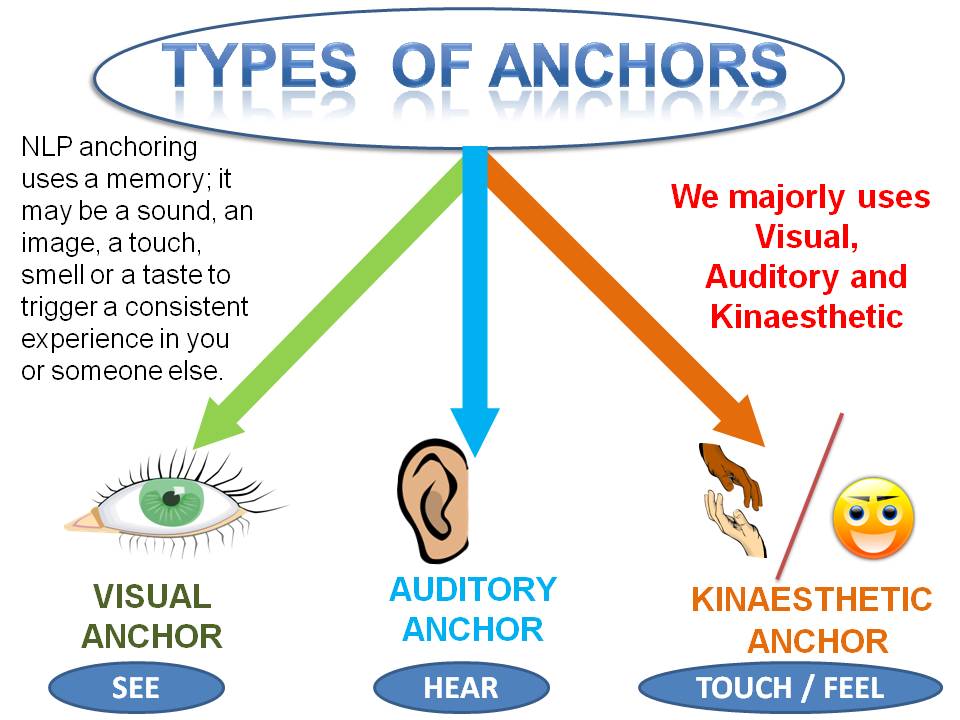
Recognizing Loss Feature In Deep Understanding To ensure justness, the regressive version must have minor distinctions in initial wage offerings for candidates with the exact same credentials however different age arrays, races, or sexes. Therefore, developing methods that represent nuanced distinctions amongst groups rather than focusing exclusively on binary outcomes can be a notable payment in this area [147] Finally, With the objective of exact image classification designs, Yang et al. present a two-step method to filtering and stabilizing the circulation of photos in the preferred Imagenet dataset of people from different subgroups [91] In the filtering action, they remove improper images that strengthen harmful stereotypes or show people in degrading methods.The Mystery of ADASYN is Revealed - Towards Data Science
The Mystery of ADASYN is Revealed.

Posted: Tue, 14 Jun 2022 07:00:00 GMT [source]
3 Techniques To Reduce Model Prejudice
Firstly, lots of researches need even more discussion regarding the short article discovering and gathering procedure [29,30,31,32] Second of all, current methodologies presented in these write-ups might require to be updated as scientists proceed progressing the area [29] In this regard, it is common for some techniques to lose significance and for brand-new strategies to obtain considerable influence, shaping the direction of research in machine learning and AI. For that reason, remaining updated with the current developments is important to make certain ongoing progression and importance. Nevertheless, recognizing the procedures to guarantee justness is as crucial as understanding the numerous fairness-related terminologies. Last but not least, there is a demand for a much more standard examination and classification of fairness techniques from the viewpoint of their dealt with justness concerns.Building New Abilities For Genai Information Note
For further details, the reader is welcomed to consult Kamiran & Calders (2012 ), Hardt et al. (2016 ), Menon & Williamson (2017) and Pleiss et al. (2017 ). We can now think about 4 teams of information corresponding to (i) heaven and yellow populations and (ii) whether they did or did not repay the car loan. For each and every of these four groups we have a circulation of credit rankings (number 1). In a suitable world, the two circulations for the yellow populace would be exactly the like those for the blue population. I really hope that you currently understand the relevance of performance metrics in version analysis, and recognize a couple Fast Phobia Cure of quirky little hacks for comprehending the spirit of your model.Function Of Loss Features In Machine Learning Formulas
And if you're searching for books with simply one more or one fewer "feline" reference, they're wrong there on the rack anymore-- you have actually have to stroll down the block to the next library. There's an entire zoo of different range metrics out there, but these two, Euclidean distance and cosine range, are both you'll face most often and will offer all right for establishing your instinct. You might observe, however, that this places guide (dog10, cat1) much more detailed to a (dog1, cat10) than, state (dog200, cat1). This is equivalent to forecasting our points onto a system circle and gauging the ranges along the arc.- Near-zero training loss happens since deep designs frequently memorize some training circumstances.
- Each upright band in this story stands for a value in one of the embedding area's 1536 dimensions.
- The technique through which we assess the efficiency of the maker discovering design is known as Prejudice Difference Decay.
- In a similar way, Prejudice and Variance assist us in criterion adjusting and making a decision better-fitted versions among a number of constructed.
- With the growing use of black-box designs, we require better techniques to evaluate and comprehend black-box model decisions.
Social Links